原文翻译自 http://www.martinfowler.com/articles/refactoring-pipelines.html ,已获得Martin Fowler(老马)授权。http://www.bilibili.com/video/av6146294/
循环一直是处理集合数据的传统方法,但是随着编程语言将函数采纳为一等公民,使得集合管道成为具有吸引力的新选择。在这篇文章中,我将用一系列例子来介绍如何利用集合管道对代码中的循环进行重构。
目录
在编程中一个常见的任务就是处理一系列对象。大部分程序员自然而然地会使用循环进行处理,这也是我们在初次学习编程的时候学到的基本控制结构。但是循环并不是做列表处理的唯一方法,近几年中,人们开始使用其他方法,例如我在这里要讲的集合管道。这种模式经常被考虑为函数式编程的一部分,但是我已经在Smalltalk编程时大量使用。伴随着面向对象编程开始支持各种lambda和函数库,使得一等函数更容易进行编程,这也使得集合管道方法变为一个令人心动的选择。
我将使用一个简单的循环作为例子,来展示我将它重构为集合管道的基本方法。
假想我们有一个读者列表,这些读者有如下数据结构。
1 2 3 4 5 class Author { public string Name { get ; set ; } public string TwitterHandle { get ; set ;} public string Company { get ; set ;} }
这个例子我们使用C#语言。
Here is the loop.
1 2 3 4 5 6 7 8 9 10 11 12 13 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) var result = new List<String> (); foreach (Author a in authors) { if (a.Company == company) { var handle = a.TwitterHandle; if (handle != null ) result.Add(handle); } } return result; } }
我将一个循环重构为集合管道的第一步,就是在循环集合中抽取变量 。[1][]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) var result = new List<String> (); var loopStart = authors; foreach (Author a in loopStart) { if (a.Company == company) { var handle = a.TwitterHandle; if (handle != null ) result.Add(handle); } } return result; } }
这个变量的设置给了我去做管道操作的起点。现在我对他还没有想出一个好名字,所以我就暂时使用这个还算有意义的名字,希望稍后再改名。
接着我开始一点点检查循环中的行为。我看到的第一件事就是条件判断,我可以使用一个过滤(filter)操作将它放入管道中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) var result = new List<String> (); var loopStart = authors .Where(a => a.Company == company); foreach (Author a in loopStart) { var handle = a.TwitterHandle; if (handle != null ) result.Add(handle); } return result; } }
我看到循环操作的下一部分就是处理Twitter handle,而不是author,所以我可以使用一个映射(map)操作。 [2][]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) var result = new List<String> (); var loopStart = authors .Where(a => a.Company == company) .Select(a => a.TwitterHandle); foreach (string handle in loopStart) { if (handle != null ) result.Add(handle); } return result; } }
循环的下一步是另一个条件判断,同样我可以把他改为filter操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) var result = new List<String> (); var loopStart = authors .Where(a => a.Company == company) .Select(a => a.TwitterHandle) .Where (h => h != null ); foreach (string handle in loopStart) { result.Add(handle); } return result; } }
到现在为止,所有循环做的事情就是在把循环集合中的所有结果添加到结果集合中,因此我可以删除循环并且仅仅返回管道结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) return authors .Where(a => a.Company == company) .Select(a => a.TwitterHandle) .Where (h => h != null ); } }
这就是代码的最终状态。
1 2 3 4 5 6 7 8 class Author {static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company ) return authors .Where(a => a.Company == company) .Select(a => a.TwitterHandle) .Where (h => h != null ); } }
我之所以喜欢集合管道,是因为我可以根据列表元素在管道中流动而看到逻辑的流向。对我来说,它非常接近我对循环结果的定义,“从读者们中选择那些有公司的,然后获取他们的twitter handler并且删除空的handle。”
更进一步来说,在拥有不同语法与不同管道操作名字的编程语言中都有类似的代码风格。
Java
1 2 3 4 5 6 7 public List<String> twitterHandles (List<Author> authors, String company) { return authors.stream() .filter(a -> a.getCompany().equals(company)) .map(a -> a.getTwitterHandle()) .filter(h -> null != h) .collect(toList()); }
Ruby
1 2 3 4 5 6 def twitter_handles authors, company authors .select {|a | company == a.company} .map {|a | a.twitter_handle} .reject {|h | h.nil ?} end
不过这符合另一个例子,我希望用compact来替换最后的reject。
Clojure
1 2 3 4 5 6 (defn twitter-handles [authors company] (->> (filter = :company %))) (map :twitter-handle ) (remove nil ?)))
F#
1 2 3 4 5 let twitterHandles (authors : seq < Author> , company : string ) = authors |> Seq.filter(fun a -> a.Company = company) |> Seq.map(fun a -> a.TwitterHandle) |> Seq.choose (fun h -> h)
再次说明,如果不是我顾及到去匹配其他例子中的结构,我会将map与choose结合为一个步骤。
我发现一旦我习惯于用管道思维去思考,我甚至可以在不熟悉的语言中快速应用它。既然基本方式是一样的,将它们从不熟悉的语法和函数名翻译过来也是相对简单的。
一旦你具有某些可以描述为管道的行为,那么就可以通过重新编排管道中步骤来进行重构。 一个例子就是如果map后紧跟一个filter,你通常可以像下面这样将filter挪到map前面。
1 2 3 4 5 6 7 class Author ...static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company) { return authors .Where(a => a.Company == company) .Where (a => a.TwitterHandle != null ) .Select(a => a.TwitterHandle); }
当你有两个相邻的filter时,你可以使用一个连接(conjunction)将他们合为一个。[4][]
1 2 3 4 5 6 class Author ...static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company) { return authors .Where(a => a.Company == company && a.TwitterHandle != null ) .Select(a => a.TwitterHandle); }
一旦我有了一个用C#实现的由简单filter和map构成的管道,我就可以使用linq表达式来替换他。
1 2 3 4 class Author ...static public IEnumerable<String> TwitterHandles (IEnumerable<Author> authors, string company) { return from a in authors where a.Company == company && a.TwitterHandle != null select a.TwitterHandle; }
我认为linq表达式是某种形式的列表推导式(list comprehension),类似地你可以在任何支持列表推导式列表的编程语言中像这样来使用。这仅仅是区别在于你更喜欢列表推导式的形式还是管道的形式(我个人更喜欢管道的形式)。 一般来说管道的功能更强大,因为你没有办法将所有的管道都重构为列表推导式。
作为第二个例子,我将重构一个简单的双重嵌套循环。假设我有一个在线系统允许读者看书。我有一个数据服务,它可以告诉我在某个特殊的日期每个读者读的哪些书。这个数据服务返回一些哈希,键是读者ID,而值是书籍ID的集合。
1 2 3 interface DataService ... { Map<String, Collection<String>> getBooksReadOn (Date date) ; }
在这个例子中,我将切换到Java语言因为我受够了首字母大写的方法名。
原始循环如下。
1 2 3 4 5 6 7 8 9 10 11 12 public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Set<String> result = new HashSet <>(); Map<String, Collection<String>> data = dataService.getBooksReadOn(date); for (Map.Entry<String, Collection<String>> e : data.entrySet()) { for (String bookId : books) { if (e.getValue().contains(bookId) && readers.contains(e.getKey())) { result.add(e.getKey()); } } } return result; }
我通常的第一步,是在循环集合中抽取变量 。
1 2 3 4 5 6 7 8 9 10 11 12 13 public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Set<String> result = new HashSet <>(); Map<String, Collection<String>> data = dataService.getBooksReadOn(date); final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet(); for (Map.Entry<String, Collection<String>> e : entries) { for (String bookId : books) { if (e.getValue().contains(bookId) && readers.contains(e.getKey())) { result.add(e.getKey()); } } } return result; }
我非常乐意做这样的改动,是因为IntelliJ这个工具的自动化重构功能帮助我避免了输入这些粗糙的类型表达式。
当我把最初的集合变为一个变量后,我就可以着手于循环元素了。因为所有的工作都是在内部的判定条件中完成的,所以我从第二个语句进行开始,把它的判定逻辑先变成一个过滤器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Set<String> result = new HashSet <>(); Map<String, Collection<String>> data = dataService.getBooksReadOn(date); final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet().stream() .filter(e -> readers.contains(e.getKey())) .collect(Collectors.toSet()); for (Map.Entry<String, Collection<String>> e : entries) { for (String bookId : books) { if (e.getValue().contains(bookId) )) { result.add(e.getKey()); } } } return result; }
在Java的streams库中,管道需要以终端来结束(例如一个收集器collector)。
另一个语句的挪动会更微妙,因为它引用了一个内部循环变量。这个语句是用来验证在字典记录中是否包含在方法参数中传入的书籍列表。我可以通过使用一个集合交集来做这样的事情。虽然Java核心类库中不包含一个集合交集的方法,我依然可以使用一些通用的基于Java集合类型的插件(例如Guava 或者 Apache Commons )来实现。因为这只是一个简单的教学实例,我将写一个粗略的实现。
1 2 3 4 5 6 class Utils ...public static <T> Set<T> intersection (Collection<T> a, Collection<T> b) { Set<T> result = new HashSet <T>(a); result.retainAll(b); return result; }
这里是可以工作的,但是如果是重大的项目,我将会使用一个通用库。
现在我可以将这个语句从循环挪到管道中了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Set<String> result = new HashSet <>(); Map<String, Collection<String>> data = dataService.getBooksReadOn(date); final Set<Map.Entry<String, Collection<String>>> entries = data.entrySet().stream() .filter(e -> readers.contains(e.getKey())) .filter(e -> !Utils.intersection(e.getValue(), books).isEmpty()) .collect(Collectors.toSet()); for (Map.Entry<String, Collection<String>> e : entries) { for (String bookId : books) { result.add(e.getKey()); } } return result; }
现在循环所做的事情只是返回一个字典记录的key,所以我可以在管道中添加一个map操作来去掉循环中的剩余部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Set<String> result = new HashSet <>(); Map<String, Collection<String>> data = dataService.getBooksReadOn(date); result = data.entrySet().stream() .filter(e -> readers.contains(e.getKey())) .filter(e -> !Utils.intersection(e.getValue(), books).isEmpty()) .map(e -> e.getKey()) .collect(Collectors.toSet()); return result; }
接下来我可以使用内联临时变量 方法来简化返回结果。
1 2 3 4 5 6 7 8 9 10 public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Map<String, Collection<String>> data = dataService.getBooksReadOn(date); return data.entrySet().stream() .filter(e -> readers.contains(e.getKey())) .filter(e -> !Utils.intersection(e.getValue(), books).isEmpty()) .map(e -> e.getKey()) .collect(Collectors.toSet()); }
观察对于交集的使用,我发现它是相当复杂的。当我读到它的时候我需要仔细考虑它在做什么,这就意味着我需要把它抽象出来。[5][]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Utils ...public static <T> boolean hasIntersection (Collection<T> a, Collection<T> b) { return !intersection(a,b).isEmpty(); } class Service ...public Set<String> getReadersOfBooks (Collection<String> readers, Collection<String> books, Date date) { Map<String, Collection<String>> data = dataService.getBooksReadOn(date); return data.entrySet().stream() .filter(e -> readers.contains(e.getKey())) .filter(e -> Utils.hasIntersection(e.getValue(), books)) .map(e -> e.getKey()) .collect(Collectors.toSet()); }
当你需要去做类似工作时就会暴露面向对象编程的缺点。有时候在静态工具类方法和普通对象的方法之间互相切换会让人感觉有些尴尬。在其他语言中,我有办法能够让它看起来像stream类的一个方法,但是在Java中却做不到。
尽管有这个问题,我仍然发现管道是比列表推导式要容易。尽管我可以将多个过滤器结合成一个,但是我常常发现把每个过滤器当做单个元素要容易理解得多。
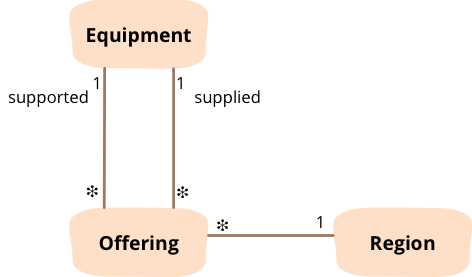
下一个例子中,针对某个特定地区利用简单条件来标识推荐的装备。为了理解它是干什么的,我需要解释一下领域模型。我们有一个组织给不同地区提供装备。当你请求一些装备时,你可能能得到完全满足需要的装备,但是经常你会的得到一个能够满足你大部分要求的替代品,但或许没那么好。我们用一个更容易联想的例子:你在波士顿,你想要一个吹雪机,但是如果在商店里没有吹雪机,你可能会得到一个雪铲。但是如果你是在迈阿密,他们甚至根本不提供吹雪机,所以你只会得到雪铲。我们通过以下三个类来描述这个数据模型。
图1: 每个供给实例都代表针对某个地区对某种设备的需求而提供的特定设备
我们可能会看到如下数据:
1 2 3 4 5 6 products: [ 'snow-blower', 'snow-shovel'] regions: [ 'boston', 'miami'] offerings: { region: 'boston', supported: 'snow-blower', supplied: 'snow-blower'} { region: 'boston', supported: 'snow-blower', supplied: 'snow-shovel'} { region: 'miami', supported: 'snow-blower', supplied: 'snow-shovel'}
我们将要看到的代码是标识某些装备是优先提供的,意味着这个供给是某个地区的优先供给。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Service ...var checkedRegions = new HashSet <Region>();foreach (Offering o1 in equipment.AllOfferings()) { Region r = o1.Region; if (checkedRegions.Contains(r)) { continue ; } Offering possPref = null ; foreach(var o2 in equipment.AllOfferings(r)) { if (o2.isPreferred) { possPref = o2; break ; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } possPref.isPreferred = true ; checkedRegions.Add(r); }
这个例子是用C#写的,因为我是个出尔反尔的人。
我怀疑循环中是有一些容易理解的逻辑,我希望通过重构能够让那些逻辑更易理解。
我的第一步是在外层循环中应用抽取变量 去初始化循环变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Service ...var loopStart = equipment.AllOfferings(); var checkedRegions = new HashSet <Region>();foreach (Offering o1 in loopStart) { Region r = o1.Region; if (checkedRegions.Contains(r)) { continue ; } Offering possPref = null ; foreach(var o2 in equipment.AllOfferings(r)) { if (o2.isPreferred) { possPref = o2; break ; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } possPref.isPreferred = true ; checkedRegions.Add(r); }
接下来我观察了循环的第一部分。它有一个控制变量checkedRegions, 循环语句使用这个变量来标记已经处理过的regions来避免多次处理。 我感觉到了一些不好的味道,但是它也建议loop变量o1只是用于获取region r的一个垫脚石。我通过在编辑器中高亮o1变量得到了确认。当我明白这一点之后,我明白我可以使用map来简化这个部分。、
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Service ...var loopStart = equipment.AllOfferings() .Select(o => o.Region); var checkedRegions = new HashSet <Region>();foreach (Region r in loopStart) { if (checkedRegions.Contains(r)) { continue ; } Offering possPref = null ; foreach(var o2 in equipment.AllOfferings(r)) { if (o2.isPreferred) { possPref = o2; break ; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } possPref.isPreferred = true ; checkedRegions.Add(r); }
现在我可以讨论这个checkedRegions控制变量了。循环中使用这个变量来避免多次处理某个region。我不清楚去检查一个region的操作是不是幂等的,如果是,我可能会完全避免做这样的检查(同时我会衡量这样做对性能是否有明显的影响)。由于我不确定,我决定保留那部分逻辑,特别是在管道中去避免重复内容是微小的改动。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Service ...var loopStart = equipment.AllOfferings() .Select(o => o.Region) .Distinct(); foreach (Region r in loopStart) { Offering possPref = null ; foreach(var o2 in equipment.AllOfferings(r)) { if (o2.isPreferred) { possPref = o2; break ; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } possPref.isPreferred = true ; }
下一步需要决定的是possPref变量。我认为处理为一个自有方法会更简单,所以对它应用提取方法 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Service ...var loopStart = equipment.AllOfferings() .Select(o => o.Region) .Distinct(); foreach (Region r in loopStart) { var possPref = possiblePreference(equipment, r); possPref.isPreferred = true ; } static Offering possiblePreference (Equipment equipment, Region region) { Offering possPref = null ; foreach (var o2 in equipment.AllOfferings(region)) { if (o2.isPreferred) { possPref = o2; break ; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } return possPref; }
我将循环集合提取到一个变量中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { Offering possPref = null ; var allOfferings = equipment.AllOfferings(region); foreach (var o2 in allOfferings) { if (o2.isPreferred) { possPref = o2; break ; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } return possPref; }
现在循环已经在它自己的函数中,我可以使用return而不是一个break
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { Offering possPref = null ; var allOfferings = equipment.AllOfferings(region); foreach (var o2 in allOfferings) { if (o2.isPreferred) { return o2; } else { if (o2.isMatch || possPref == null ) { possPref = o2; } } } return possPref; }
第一个条件检查是查找第一个offering,如果存在的话这个条件将成立。这是检测操作需要做的工作(在C#中叫做First)[6][]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { Offering possPref = null ; var allOfferings = equipment.AllOfferings(region); possPref = allOfferings.FirstOrDefault(o => o.isPreferred); if (null != possPref) return possPref; foreach (var o2 in allOfferings) { if (o2.isMatch || possPref == null ) { possPref = o2; } } return possPref; }
最后一个条件判断就十分微妙了。它将possPref设置为列表中第一个offering的内容,但是后续通过isMatch检查的值又会将其覆盖。但是即使isMatch成立,循环也不会跳出(break),所以后续通过isMatch的结果继续会覆盖这个值。为了重现这个行为,我需要使用LastOrDefault方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { Offering possPref = null ; var allOfferings = equipment.AllOfferings(region); possPref = allOfferings.FirstOrDefault(o => o.isPreferred); if (null != possPref) return possPref; possPref = allOfferings.LastOrDefault(o => o.isMatch); if (null != possPref) return possPref; foreach (var o2 in allOfferings) { if ( possPref == null ) { possPref = o2; } } return possPref; }
该循环剩下部分是要返回第一个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { Offering possPref = null ; var allOfferings = equipment.AllOfferings(region); possPref = allOfferings.FirstOrDefault(o => o.isPreferred); if (null != possPref) return possPref; possPref = allOfferings.LastOrDefault(o => o.isMatch); if (null != possPref) return possPref; return allOfferings.First(); }
我个人习惯在函数返回值部分对于任何类型的返回值都使用result命名,所以这里我进行了重命名 。
1 2 3 4 5 6 7 8 9 10 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { Offering result = null ; var allOfferings = equipment.AllOfferings(region); result = allOfferings.FirstOrDefault(o => o.isPreferred); if (null != result) return result; result = allOfferings.LastOrDefault(o => o.isMatch); if (null != result) return result; return allOfferings.First(); }
我现在有理由对函数possiblePreference表示满意,我认为它十分清晰地在它的领域内陈述了逻辑。我再也不需要为了了解这个程序的目的而去了解整个代码的逻辑了。
但是因为我是使用C#语言,我还可以使用空结合操作符??去让它变得更可读。这个操作允许我将几个表达式链接起来,然后返回第一个非空的值。
1 2 3 4 5 6 7 class Service ...static Offering possiblePreference (Equipment equipment, Region region) { var allOfferings = equipment.AllOfferings(region); return allOfferings.FirstOrDefault(o => o.isPreferred) ?? allOfferings.LastOrDefault(o => o.isMatch) ?? allOfferings.First(); }
在非严格类型编程语言中,null被当做false处理,你可以使用or操作符达到同样的效果。另一个选择就是将一等函数组合起来(那会是另外一个完整的话题)。
现在我们回到外层循环,现在它如下结构:
1 2 3 4 5 6 7 8 class Service ...var loopStart = equipment.AllOfferings() .Select(o => o.Region) .Distinct(); foreach (Region r in loopStart) { var possPref = possiblePreference(equipment, r); possPref.isPreferred = true ; }
我可以在管道中使用我新定义的函数possiblePreference。
1 2 3 4 5 6 7 8 9 10 class Service ...var loopStart = equipment.AllOfferings() .Select(o => o.Region) .Distinct() .Select(r => possiblePreference(equipment, r)) ; foreach (Offering o in loopStart) { o.isPreferred = true ; }
请注意将分号保留在单独一行的形式。我在使用长管道的时候经常使用它,因为这样可以让管理管道变得更容易。
通过重命名循环初始变量,结果的读取就变得更清晰了。
1 2 3 4 5 6 7 8 9 class Service ...var preferredOfferings = equipment.AllOfferings() .Select(o => o.Region) .Distinct() .Select(r => possiblePreference(equipment, r)) ; foreach (Offering o in preferredOfferings) { o.isPreferred = true ; }
代码变成这样我已经十分满意了,但是我还是可以按如下方式把foreach行为放入管道中。
1 2 3 4 5 6 7 8 9 class Service ... {equipment.AllOfferings() .Select(o => o.Region) .Distinct() .Select(r => possiblePreference(equipment, r)) .ToList() .ForEach(o => o.isPreferred = true ) ; }
这是一个更有争议的步骤。许多人并不喜欢在管道中带着副作用去使用函数。这就是为什么我需要使用中间的tolist操作,因为Foreach操作在IEnumerable不存在。在副作用的问题上,使用Tolist也在提醒我们不论何时我们使用副作用操作,我们将会在对管道的求值中失去惰性。(在这里这并不是个问题,因为整个管道的焦点是去挑选一些可以修改的对象)。
但是不管使用何种方法,我发现现在已经比原始的循环要清晰的多。前面的循环的例子是足够清晰去理解,但是它还是需要人花一些时间去思考与理解它在做什么。当然将possiblePreference提取出来是让它变得清晰的一个重要因素,你仍然可以保持循环并做类似的抽象,尽管我肯定希望避免在逻辑中乱转,从而保证我能够避免重复的区域。
在这个例子中,我将查看一些将飞机晚点信息汇总的代码。这段代码一些准点航班的记录开始,这些数据来自于美国交通运输部交通统计局。经过一些初步的数据筛选,结果数据如下显示:
1 2 3 4 5 6 7 8 9 10 11 [ { "origin" :"BOS" ,"dest" :"LAX" ,"date" :"2015-01-12" ,"number" :"25" ,"carrier" :"AA" ,"delay" :0.0 ,"cancelled" :false }, { "origin" :"BOS" ,"dest" :"LAX" ,"date" :"2015-01-13" ,"number" :"25" ,"carrier" :"AA" ,"delay" :0.0 ,"cancelled" :false }, ... ]
这就是处理这些数据的循环代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 export function airportData ( const data = flightData (); const count = {}; const cancellations = {}; const totalDelay = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; cancellations[airport] = 0 ; totalDelay[airport] = 0 ; } count[airport]++; if (row.cancelled ) { cancellations[airport]++ ; } else { totalDelay[airport] += row.delay ; } } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = totalDelay[i] / (count[i] - cancellations[i]); result[i].cancellationRate = cancellations[i] / count[i]; } return result; }
这个例子使用JavaScript代码(node上的es6), 因为现在几乎所有事情都是使用JavaScript代码来编写。
这个循环通过总结航班数据中目的地机场(dest)并且计算取消率来定义延误。这个处理的核心就是通过目的地来对航班数据分组,这正好适用管道中的分组操作。因此我的第一步就是去使用一个变量来捕获这个分组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import from 'underscore' ;export function airportData ( const data = flightData (); const working = _.groupBy (data, r =>dest ); const count = {}; const cancellations = {}; const totalDelay = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; cancellations[airport] = 0 ; totalDelay[airport] = 0 ; } count[airport]++; if (row.cancelled ) { cancellations[airport]++; } else { totalDelay[airport] += row.delay ; } } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = totalDelay[i] / (count[i] - cancellations[i]); result[i].cancellationRate = cancellations[i] / count[i]; } return result; }
在这个步骤中有几个事情需要说明。首先,我现在还对它想不出一个好名字,所以我暂时叫他working。第二,尽管Javascript的数组中有一些很好的针对集合管道的操作,但它还是缺少分组操作符。我本来可以自己写一个,但是我将使用underscore库, 它已经是Javascript领域一个非常有用的工具。
Count变量记录对每个目的地机场有多少飞行记录。 我可以使用一个map操作符在管道中更简单地计算出来。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 export function airportData ( const data = flightData (); const working = _.chain (data) .groupBy (r =>dest ) .mapObject ((val, key ) => {return {count : val.length }}) .value () ; const count = {}; const cancellations = {}; const totalDelay = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; cancellations[airport] = 0 ; totalDelay[airport] = 0 ; } count[airport]++; if (row.cancelled ) { cancellations[airport]++; } else { totalDelay[airport] += row.delay ; } } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = totalDelay[i] / (working[i].count - cancellations[i]); result[i].cancellationRate = cancellations[i] / working[i].count ; } return result; }
为了能够像例子中能够在underscore中做多步骤管道,我必须以chain(链)函数来做为管道的开始。这个步骤能够保证在管道中的每一步都是被underscore包装的,然后我就可以使用一个方法链去构建这个管道。不过他的负面作用就是我需要使用最末端的值来将它从数组中取出。
这个map操作并不是一个标准map操作,因为它是对一个javascript对象的内容进行操作,所以它必须是一个哈希map,因此这个映射函数就像在操作一些key/value对。在Underscore库中,我使用mapObject函数来做类似的事情。
通常来说,当我把一个行为挪到管道中时,我更乐意将控制变量完全去除,但是控制变量经常要去跟踪所需key,我暂时把它留在这里,直到我处理完其他所有的计算。
下一步我将处理取消业务变量,这时我可以删除它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 export function airportData ( const data = flightData (); const working = _.chain (data) .groupBy (r =>dest ) .mapObject ((val, key ) => { return { count : val.length , cancellations : val.filter (r =>cancelled ).length } }) .value () ; const count = {}; const cancellations = {}; const totalDelay = {}; const cancellations = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; cancellations[airport] = 0 ; totalDelay[airport] = 0 ; } count[airport]++; if (row.cancelled ) { cancellations[airport]++; } else { totalDelay[airport] += row.delay ; } } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = totalDelay[i] / (working[i].count - working[i].cancellations ); result[i].cancellationRate = working[i].cancellations / working[i].count ; } return result; }
该映射函数变得越来越长了,是使用提取方法 的时候了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 export function airportData ( const data = flightData (); const summarize = function (rows ) { return { count : rows.length , cancellations : rows.filter (r =>cancelled ).length } } const working = _.chain (data) .groupBy (r =>dest ) .mapObject ((val, key ) => summarize (val)) .value () ; const count = {}; const totalDelay = {} for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; totalDelay[airport] = 0 ; } count[airport]++; if (row.cancelled ) { } else { totalDelay[airport] += row.delay ; } } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = totalDelay[i] / (working[i].count - working[i].cancellations ); result[i].cancellationRate = working[i].cancellations / working[i].count ; } return result; }
在函数内部将一个函数赋值给一个变量是JavaScript中嵌套函数的方式,以将其作用域限制在airportData函数内。我可以想象这个函数将会变得更有用,不过那是稍后的重构中需要考虑的方面。
现在我们来计算总延迟。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 export function airportData ( const data = flightData (); const summarize = function (rows ) { return { count : rows.length , cancellations : rows.filter (r =>cancelled ).length , totalDelay : rows.filter (r =>cancelled ).reduce ((acc,each ) => acc + each.delay , 0 ) } } const working = _.chain (data) .groupBy (r =>dest ) .mapObject ((val, key ) => summarize (val)) .value () ; const count = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; } count[airport]++; } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations ); result[i].cancellationRate = working[i].cancellations / working[i].count ; } return result; }
在Lambda中用于计算总延时的表达式映射了原来的方程,使用了一个reduce操作去计算总和。我经常觉得首先使用map会让它更易读。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 export function airportData ( const data = flightData (); const summarize = function (rows ) { return { count : rows.length , cancellations : rows.filter (r =>cancelled ).length , totalDelay : rows.filter (r =>cancelled ).map (r =>delay ).reduce ((a,b ) => a + b) } } const working = _.chain (data) .groupBy (r =>dest ) .mapObject ((val, key ) => summarize (val)) .value () ; const count = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; } count[airport]++; } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations ); result[i].cancellationRate = working[i].cancellations / working[i].count ; } return result; }
这个重写并不是什么大事,但是我逐渐倾向于它。那个Lambda表达式也有点长了,不过我并不认为现在
我也在利用这个机会,通过重命名将Lambda替换为summarize函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 export function airportData ( const data = flightData (); const summarize = function (rows ) { return { count : rows.length , cancellations : rows.filter (r =>cancelled ).length , totalDelay : rows.filter (r =>cancelled ).map (r =>delay ).reduce ((a,b ) => a + b) } } const working = _.chain (data) .groupBy (r =>dest ) .mapObject (summarize) .value () ; const count = {}; for (let row of data) { const airport = row.dest ; if (count[airport] === undefined ) { count[airport] = 0 ; } count[airport]++; } const result = {}; for (let i in count) { result[i] = {}; result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations ); result[i].cancellationRate = working[i].cancellations / working[i].count ; } return result; }
现在所有依赖的数据已经被移除了,我已经可以删除计数器了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 export function airportData ( const data = flightData (); const summarize = function (rows ) { return { count : rows.length , cancellations : rows.filter (r =>cancelled ).length , totalDelay : rows.filter (r =>cancelled ).map (r =>delay ).reduce ((a,b ) => a + b) } } const working = _.chain (data) .groupBy (r =>dest ) .mapObject (summarize) .value () ; const result = {}; for (let i in working) { result[i] = {}; result[i].meanDelay = working[i].totalDelay / (working[i].count - working[i].cancellations ); result[i].cancellationRate = working[i].cancellations / working[i].count ; } return result; }
现在我把我的注意力转向第二个循环,它本质上对于通过map映射去计算它的两个值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 export function airportData ( const data = flightData (); const summarize = function (rows ) { return { count : rows.length , cancellations : rows.filter (r =>cancelled ).length , totalDelay : rows.filter (r =>cancelled ).map (r =>delay ).reduce ((a,b ) => a + b) } } const formResult = function (row ) { return { meanDelay : row.totalDelay / (row.count - row.cancellations ), cancellationRate : row.cancellations / row.count } } let working = _.chain (data) .groupBy (r =>dest ) .mapObject (summarize) .mapObject (formResult) .value () ; return working; }
上面这些都做完了,我可以使用内联临时变量 去继续做一些重命名和清理工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 export function airportData ( const data = flightData (); const summarize = function (flights ) { return { numFlights : flights.length , numCancellations : flights.filter (f =>cancelled ).length , totalDelay : flights.filter (f =>cancelled ).map (f =>delay ).reduce ((a,b ) => a + b) } } const formResult = function (airport ) { return { meanDelay : airport.totalDelay / (airport.numFlights - airport.numCancellations ), cancellationRate : airport.numCancellations / airport.numFlights } } return _.chain (data) .groupBy (r =>dest ) .mapObject (summarize) .mapObject (formResult) .value () ; }
作为经常发生的一种情况,最后一个函数的高可读性来自于抽取函数 。不过我也发现对分组操作很有助于澄清函数的目的和提取的过程。
如果数据来自于一个关系型数据库并且存在性能问题的时候,这个重构还能带来潜在的益处。当我把一个循环重构为一个集合管道时,我呈现的这个变形过程更像是一种类似于SQL的形式。在这个例子中,我可能会从数据库中拉取出很多数据,而重构后的代码使之更易于考虑将分组和第一级总结逻辑放到SQL中,这将能够降低我传输的数据量。通常来说,我更倾向于将处理逻辑放在应用层代码中而不是SQL中,这样如果我能够衡量一个巨大的性能提升的时候,我可以着手去做性能优化。不过这个也再次强调了一点:当你的代码结构清晰时,你更容易去做代码优化。这也是为什么我所知的所有性能优化行家都将”简化至上”强调为代码性能优化的重要基础。
下一个例子,我将看看一些检查一个人是否拥有一些需要标识的代码。很多系统都会依赖一些希望是唯一的ID(例如客户ID)来标识某个人。但是在很多领域中,你需要处理很多种的标识模式,一个人应该拥有多重模式的标识。例如一个城镇政府就希望一个人能够同时拥有town ID、state ID和National ID。
图2:一个人拥有不同身份模式的标识的数据模型
这种情况下的数据结构是非常简单的。 Person类拥有标识对象的一个集合。标识有一个域来存放模式和一些值。但是通常会有一些其他约束不能仅仅被数据模型进行强制实施,这些约束将会被一些验证函数来检查,如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Person ...def check_valid_ids required_schemes, note: nil note |Notification .new note.add_error "has no ids" if @ids .size < 1 used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
这个例子是用Ruby编写的,因为我喜欢用Ruby编程
有其他的一些对象在支持这个循环。Identifier类知道它自己的模式、值以及是否为Void——意味着逻辑上是被删除的(但是它是仍然保留在数据库中的)。同时在其中还有一个通知对象去跟踪中间发生的错误。
1 2 3 4 5 6 7 8 class Identifier attr_reader :scheme , :value def void? … class Notification def add_error e…
我感觉到这个函数的坏味道就是在循环中同时做两件事情。它在寻找重复的identifiers(在dups集合中),同时寻找需要的但是缺失的模式(在required_schemes)中。程序员经常要在同一个集合对象中做两件事,于是决定使用相同的循环来处理。一个原因是代码要求建立一个循环,如果将它重复两次将会看起来非常丢人。现代的循环构造函数和管道则消除了这个负担。另一个更有害的原因是对于性能的担心。显而易见的很多性能上的热点都会包含循环,并且也有些将循环融合之后性能能够提高的例子。但是这在我们所写的循环中只占了非常小的一部分,因此我们应该遵循编程中的常规准则。 集中精力于清晰化代码而不是性能,除非你已经有可衡量的巨大的性能问题。 如果你真有性能方面的问题,则修复问题要优先于清晰化代码,但是这种例子非常少见。
当我面对一个在做两件事情的循环时,我毫不犹豫地去复制循环去改进代码清晰度。通过性能分析来触发我去做代码重构是非常少见的。
我重构的第一步就是所谓的拆分循环。当我开始做的时候,我将循环以及和它有联系的代码置入同一代码块,并对其应用提取方法 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Person ...def check_valid_ids required_schemes, note: nil note |Notification .new note.add_error "has no ids" if @ids .size < 1 return inner_check_valid_ids required_schemes, note: note end def inner_check_valid_ids required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
这块抽象出来的方法在做两件事情,现在我想重复这块代码去为两个不同方法形成单独的脚手架,这样每个方法只做一个事情。如果我重复这段代码并且每个都调用一次,这会导致我累积的通知中包含两次错误。我可以通过删除每个重复代码中的无关更新来避免这种情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 class Person ...def check_valid_ids required_schemes, note: nil note |Notification .new note.add_error "has no ids" if @ids .size < 1 check_no_duplicate_ids required_schemes, note: note check_all_required_schemes required_schemes, note: note end def check_no_duplicate_ids required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end end return note end def check_all_required_schemes required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
删除双重更新非常重要,这样我在重构过程中测试全部通过。
这个重复的结果是非常丑陋的,但是现在我可以独立的解决每个方法存在的问题,删除每个方法中并不需要的部分。
我将以非重复的部分开始,我可以在几步之内删除掉大块的代码,并且在每一步之后都进行测试去确保我不会犯错。我先删除最后部分使用required_schemes的代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Person ...def check_no_duplicate_ids required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
接下来我删除条件判断中不需要的分支。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Person ...def check_no_duplicate_ids required_schemes, note: nil used = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
这时我可以,或者说我应该删除不需要的required_schemes变量,但是我没有做,你将在最后看到它被清理了。
我继续我常用的提取变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Person ...def check_no_duplicate_ids required_schemes, note: nil used = [] dups = [] input = @ids for id in input next if id.void? if used.include ?(id.scheme) dups << id.scheme end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
我也可以接着给输入变量增加一个过滤器,删除那些略过空identifier的代码行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class Person ...def check_no_duplicate_ids required_schemes, note: nil used = [] dups = [] input = @ids .reject{|id | id.void?} for id in input if used.include ?(id.scheme) dups << id.scheme end used << id.scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
继续研究循环,我可以看到它使用scheme而不是id,所以我使用管道去将id映射到schemes中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Person ...def check_no_duplicate_ids required_schemes, note: nil used = [] dups = [] input = @ids .reject{|id | id.void?} .map {|id | id.scheme} for scheme in input if used.include ?(scheme) dups << scheme end used << scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
这时我已经将循环的主体简化到只有删除重复部分的行为了。同时也有一个管道的方式去寻找重复部分,就是针对scheme分组然后过滤出来出现多于一次的部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Person ...def check_no_duplicate_ids required_schemes, note: nil used = [] dups = [] input = @ids .reject{|id | id.void?} .map {|id | id.scheme} .group_by {|s | s} .select {|k,v | v.size > 1 } .keys for scheme in input dups << scheme used << scheme end if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
现在管道的输出部分就已经是重复了,我可以删除输入变量并且将管道赋值给这个变量(并且删除现在不需要的变量)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Person ...def check_no_duplicate_ids required_schemes, note: nil dups = @ids .reject{|id | id.void?} .map {|id | id.scheme} .group_by {|s | s} .select {|k,v | v.size > 1 } .keys if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end
这段代码提供了一个漂亮的管道,但是里面也有一个麻烦元素。在管道中的最后三步是去删除重复结果,但是这部分知识只在我脑袋里,而不在代码中。我需要利用提取方法 把它移到代码中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Person ...def check_no_duplicate_ids required_schemes, note: nil dups = @ids .reject{|id | id.void?} .map {|id | id.scheme} .duplicates if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end class Array …def duplicates self .group_by {|s | s} .select {|k,v | v.size > 1 } .keys end
这里我使用Ruby的特性给一个存在的类增加了一个方法(即猴子补丁方法)。 我也可以使用最新版的ruby中提供的refinement功能来实现这个目的。但是很多面向对象的语言并不支持猴子补丁(monkey-patching)方法,在这种情况下我需要跟随这部分代码去使用一个本地定义的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Person ...def check_no_duplicate_ids required_schemes, note: nil schemes = @ids .reject{|id | id.void?} .map {|id | id.scheme} if duplicates(schemes).size > 0 note.add_error "duplicate schemes: " + duplicates(schemes).join(", " ) end return note end def duplicates anArray anArray .group_by {|s | s} .select {|k,v | v.size > 1 } .keys end
对于管道来说,针对Person来定义一个方法即将其添加到一个数组中,这个效果并不是很好。但是通常来说我们并不能把一个方法添加到数组中,有时候是因为我们的编程语言并不支持猴子补丁(monkey-patching),有时候是因为项目标准使之变得不容易,或者因为一个方法并非通用到足以放入一个通用的列表类中。这个例子正好提醒了面向对象方式带来的妨碍,而函数式方式不绑定方法到对象上,工作得更好。
每当我有一个像这样的局部变量,我经常考虑使用利用查询替换临时变量 来将这个变量变换为一个方法,变换的结果如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Person ...def check_no_duplicate_ids required_schemes, note: nil if duplicate_identity_schemes.size > 0 note.add_error "duplicate schemes: " + duplicate_identity_schemes.join(", " ) end return note end def duplicate_identity_schemes @ids .reject{|id | id.void?} .map {|id | id.scheme} .duplicates end
我做出这样的决定是因为我觉得duplicate_identity_schemes的行为对于Person类的其他方法是有用的。但是尽管我更倾向于在查询方法中产生错误,但在这个例子中,我更倾向于把它仍然保留为一个本地变量
现在我已经清理了检查重复部分的代码。我可以开始着手检查我们需要的所有模式。下面是现有的方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Person ...def check_all_required_schemes required_schemes, note: nil used = [] found_required = [] dups = [] for id in @ids next if id.void? if used.include ?(id.scheme) dups << id.scheme else for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end used << id.scheme end if dups.size > 0 end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
就像前一方法所做的,我的第一步就是删除检查重复模式的任何代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Person ...def check_all_required_schemes required_schemes, note: nil found_required = [] for id in @ids next if id.void? for req in required_schemes if id.scheme == req found_required << req required_schemes.delete req next end end end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
为了进入这个函数的核心部分,我开始观察found_required变量。在检查重复模式的场景中,它首要感兴趣的是非空identifier的那些模式,因此我倾向于首先将这些模式存储于一个变量中,开始使用这些变量而不是继续使用ID
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Person ...def check_all_required_schemes required_schemes, note: nil found_required = [] schemes = @ids .reject{|i | i.void?} .map {|i | i.scheme} for s in schemes for req in required_schemes if s == req found_required << req required_schemes.delete req next end end end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
使用found_required的目的就是去捕获那些既在required_schemes列表中并且又存在于来自于ID的那些模式。对我来说,这个就听起来像是一个集合交集,这是任何自重集合(self-respecting collection)都应该有的函数。因此我应该能够利用它来决定found_required.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Person ...def check_all_required_schemes required_schemes, note: nil schemes = @ids .reject{|i | i.void?} .map {|i | i.scheme} found_required = schemes & required_schemes if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
不幸的是这个改动让测试失败了。我更仔细检查了那些代码,然后我发现found_required变量在后续的代码中再也没有被用到过,这就是一个僵尸变量,即它曾被使用过一次但后来放弃了,然而变量并没有被删除。所以我回退了我前面的改动然后删除了它。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Person ...def check_all_required_schemes required_schemes, note: nil schemes = @ids .reject{|i | i.void?} .map {|i | i.scheme} for s in schemes for req in required_schemes if s == req required_schemes.delete req next end end end if required_schemes.size > 0 missing_names = "" for req in required_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
现在我观察到循环是在从参数required_schemes中删除元素了。对我来说,修改这样的参数是严格的不允许的,除非他是一个集合参数(例如note参数)。 因此我立即应用使用移除向参数的赋值 来重构。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Person ...def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes.dup schemes = @ids .reject{|i | i.void?} .map {|i | i.scheme} for s in schemes for req in required_schemes if s == req missing_schemes.delete req next end end end if missing_schemes.size > 0 missing_names = "" for req in missing_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
这样做也揭示了循环正在从枚举的列表中删除元素 —— 这比修改这个参数更为糟糕
现在这一部分已经清晰了,我可以看到一个set操作是合适的,但是我需要去做的是从所需的列表中删除我们已有模式 —— 使用一个差集操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Person ...def check_all_required_schemes required_schemes, note: nil schemes = @ids .reject{|i | i.void?} .map {|i | i.scheme} missing_schemes = required_schemes - schemes if missing_schemes.size > 0 missing_names = "" for req in missing_schemes missing_names += (missing_names.size > 0 ) ? ", " + req.to_s : req.to_s end note.add_error "missing schemes: " + missing_names end return note end
现在我开始观察第二个产生错误信息的循环。这个循环只是将模式转换成字符串,然后利用逗号将他们连接起来 —— 这就是字符串连接操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Person ...def check_all_required_schemes required_schemes, note: nil schemes = @ids .reject{|i | i.void?} .map {|i | i.scheme} missing_schemes = required_schemes - schemes if missing_schemes.size > 0 missing_names = missing_schemes.join(", " ) note.add_error "missing schemes: " + missing_names end return note end
现在两个方法都已经清理完毕,每个方法已经十分清晰并且他们只做一个事情。他们都需要非空identifiers的模式列表,因此我倾向于使用提取方法 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Person ...def check_no_duplicate_ids required_schemes, note: nil dups = identity_schemes.duplicates if dups.size > 0 note.add_error "duplicate schemes: " + dups.join(", " ) end return note end def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes - identity_schemes if missing_schemes.size > 0 missing_names = missing_schemes.join(", " ) note.add_error "missing schemes: " + missing_names end return note end def identity_schemes @ids .reject{| i | i.void?} .map {|i | i.scheme} end
接下来我想做一些小的代码清理。首先我运行测试,通过检测一个集合的大小来查看集合是否为空。我总是倾向于一个更加揭露意图的empty方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Person ...def check_no_duplicate_ids required_schemes, note: nil dups = identity_schemes.duplicates unless dups.empty? note.add_error "duplicate schemes: " + dups.join(", " ) end return note end def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes - identity_schemes unless missing_schemes.empty? missing_names = missing_schemes.join(", " ) note.add_error "missing schemes: " + missing_names end return note end
这个重构我不知道叫什么好,它应该被叫做“将揭示实现的方法替换为揭示意图的方法”这样的名字。
missing_names变量无足轻重,因此我在这里将使用内联临时变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Person ...def check_no_duplicate_ids required_schemes, note: nil dups = identity_schemes.duplicates unless dups.empty? note.add_error "duplicate schemes: " + dups.join(", " ) end return note end def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes - identity_schemes unless missing_schemes.empty? note.add_error "missing schemes: " + missing_schemes.join(", " ) end return note end
我也同时非常乐意将这些语句转变为单行条件语句格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Person ...def check_no_duplicate_ids required_schemes, note: nil dups = identity_schemes.duplicates note.add_error "duplicate schemes: " + dups.join(", " ) unless dups.empty? return note end def check_all_required_schemes required_schemes, note: nil missing_schemes = required_schemes - identity_schemes note.add_error "missing schemes: " + missing_schemes.join(", " ) unless missing_schemes.empty? return note end
同样,针对这个重构并没有定义,并且这应该是专门针对Ruby语言的一种重构。
伴随着上述变化,我认为这个方法不再有单独存在的价值,因此我将内联它们,并且提取出identity_schemes方法,把它放到调用者内部。
1 2 3 4 5 6 7 8 9 10 11 class Person ...def check_valid_ids required_schemes, note: nil note |Notification .new note.add_error "has no ids" if @ids .size < 1 identity_schemes = @ids .reject{|i | i.void?}.map {|i | i.scheme} dups = identity_schemes.duplicates note.add_error("duplicate schemes: " + dups.join(", " )) unless dups.empty? missing_schemes = required_schemes - identity_schemes note.add_error "missing schemes: " + missing_schemes.join(", " ) unless missing_schemes.empty? return note end
最后一个方法比我通常使用的要长,但是我喜欢其内聚性。如果它增长到非常大的话我会希望分割它,也许采用“用方法对象来替换方法”的重构手段。尽管如此,我发现它更清晰地表述这个验证函数在检查什么错误。
上面的例子是对于这些重构方法的总结。关于集合管道是如何能够清晰那些处理集合的代码逻辑,以及如何直截了当地将循环重构为一个集合管道,我希望给你一个良好的感觉。
在任何的重构中,同样存在将一个集合管道改变为一个循环的逆向重构,不过我很少使用到它。
现在,大部分流行的编程语言都会提供一等函数,以及一组包含必要的集合管道操作库。
如果你还不习惯于集合管道,按照上面的例子将你正在使用的循环进行重构将是一个很好的练习。
如果你发现最终的管道并不比原来的循环更清晰,你经常可以还原你所做的重构。
即使你还原了你所做的重构,练习也能够教会你很多这个重构的技巧。
我曾经使用这种编程模式很久,并且发现这是一种很有价值的帮助我阅读自己代码的方式。正因如此,我认为值得花时间去发掘它,然后去看你的团队是否能够得出类似的结论。
脚注 1: 事实上,我的第一步改动是考虑在循环中应用提取方法 ,因为处理一个孤立于自己函数的循环会更容易。
2: 对于我来说,看到将一个map操作叫做“select”是非常奇怪的事情。原因是C#中管道函数式来自于linq,而其主要目的就是抽象数据库接入部分,因此方法是故意选择为类SQL。“Select”在SQL语言中是一个投射操作,因此当你把它认为是一个列选择操作时是有意义的,而你把他认为是一个映射函数时是有些奇怪的。
3: 当然这并不是一个所有能处理集合管道的编程语言的详尽的列表,所以我期望通常的抱怨都在说我没有使用JavaScript、Scala或者任何++。我并不希望这里有一长串编程语言,我只是希望用一小部分不同的语言去揭示在不熟悉的编程语言中集合管道也是十分容易去使用的。
4: 在一些例子中它需要成为一个短路,尽管在这个例子中并不适用。
5: 我经常在负的布尔值中发现这个问题。这是因为否定操作符(!)是放在表达式的开始部分,而判定(isEmpty)是放在表达式最后。在这两者中的任何一个实质性表达式,结果的解析往往都非常困难(至少对我来说)
6: 我还没有把它放入操作符列表中。
7: 如果我使用的编程语言中不存在一个能够检测最后一个元素是否通过断言的操作符,我可以首先将它翻转然后去检测第一个元素。
致谢 Kit Eason帮助我将F#的例子变得更地道。Les Ramer帮助我改进了我的C#。Richard Warburton纠正了我Java中的一些不严谨的文字。Daniel Sandbecker指出了我Ruby例子中的一个错误。Andrew Kiellor, Bruno Trecenti, David Johnston, Duncan Cragg, Karel Alfonso, Korny Sietsma, Matteo Vaccari, Pete Hodgson, Piyush Srivastava, Scott Robinson, Steven Lowe, 与 Vijay Aravamudhan通过ThoughtWorks邮件列表讨论了这个文章的草稿。
版本历史
2015-07-14 加入了identifiers例子并且最终定稿。
2015-07-07 加入了飞行数据分组的例子
2015-06-30 加入了装备提供商的例子
2015-06-25 加入了嵌套循环一节
2015-06-23 发表了第一期